 |
|
| node: | Automatic Speech Recognition |
| template: | 13 |
| parent: | Veda a technologie |
| owner: | Prospero |
| viewed by: | |
| created: | 19.01.2018 - 12:44:35 |
| updated: | 19.01.2018 - 13:15:44 |
|
cwbe coordinatez: 101 63533 8446046 ABSOLUT KYBERIA |
| permissions | |
| you: | r, |
| system: | public |
| net: | yes |
total descendants::32
total children::17
11 ❤️
| bloody | 0 |
| rucho | 0 |
| Burning A | 0 |
| CARBON IN DI... | 0 |
| mateno | 0 |
| tp | 0 |
| kiwo | 0 |
| mirex | 0 |
| kyberbubus | 0 |
| maniac | 0 |
| Prospero | 0 |
| RataFuck von... | 0 |
| Indalam | 0 |
| superpussy | 0 |
| huno | 0 |
| risko | 0 |
| čo | 2 |
| mwt | 2 |
| L4ky | 2 |
| Lester | 5 |
| asety | 5 |
| ewenka | 5 |
| tulenya | 7 |
| Thanatos | 7 |
| september | 7 |
| cocacoala | 10 |
| ode | 10 |
| paskudnyk | 11 |
| darkforce | 11 |
| grzegorz brz... | 11 |
| kredenc | 11 |
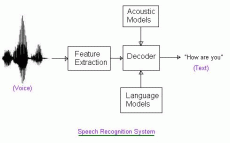
Forum o strojovom rozpoznavani reci.
Ak mate skusenosti s platformami ako Sphinx, Julius alebo Kaldi, tak sem s nimi.
Dominantne ASR systemy:
http://kaldi-asr.org/
https://github.com/julius-speech/julius
https://cmusphinx.github.io/
Hotword detection:
https://snowboy.kitt.ai/ (Snowboy Vam pobezi an Raspberry PI, bohuzial Vam vsak neumoznuje vytrenovat si vlastne modely a nuti Vas - podobne ako Apple ci Google - outsourcovat Vase hlasove data korporacii)
Datasety:
http://www.voxforge.org/
Ciel fora :: Vytvorenie vlastnych akustickych a jazykovych modelov.
Ak mate skusenosti s platformami ako Sphinx, Julius alebo Kaldi, tak sem s nimi.
Dominantne ASR systemy:
http://kaldi-asr.org/
https://github.com/julius-speech/julius
https://cmusphinx.github.io/
Hotword detection:
https://snowboy.kitt.ai/ (Snowboy Vam pobezi an Raspberry PI, bohuzial Vam vsak neumoznuje vytrenovat si vlastne modely a nuti Vas - podobne ako Apple ci Google - outsourcovat Vase hlasove data korporacii)
Datasety:
http://www.voxforge.org/
Ciel fora :: Vytvorenie vlastnych akustickych a jazykovych modelov.
There are currently 9863 K available in
2nd Guild's K-treasury.
get 1 🦆 for 5 🐘
get 1 🐘 for 1 🦆
dendrite ponuka prace :: hlada sa Wissenschaftliche Mitarbeiter(in) na Berlin University of the Arts
dendrite COVID-19 Artificial Intelligence Diagnosis Using Only Cough Recordings
dendrite Čítanka pre urodzené slečny, level 0
dendrite speech to text
dendrite 07.03.2018-14:56:02
axone main
axone neuronove siete
axone machine learning - practical. Marketing, content monetization
axone forumz
axone umela inteligencia